




Drillhole, borehole or well data (collectively termed drill data for this blog) is at the core of every Leapfrog project. The drill data object provides the primary source of data for implicit modelling and is essentially the beginning of all dynamic workflows in Leapfrog. With the release of Leapfrog Geo 2021.1, Leapfrog Works 2021.1 and Leapfrog Energy 2021.1, there is now no limit to the number of drilling data sets that can be imported to a project. An upgrade to this fundamental functionality was a large undertaking and opens a world of new workflow possibilities for you.
Leapfrog 2021.1 sees delivery of phase one of a larger drillhole, borehole and well data set upgrade, and you can expect more to come in future releases. Although this is only the first phase there are already significant advantages for modelers. For example, if the project being modelled has two sources for drilling information, converting this information into one source file can be troublesome. You can now import both drill data sets from different data sources. These data sources include Seequent Central, ODBC, acQuire, OpenGround Cloud, and old faithful CSV data.
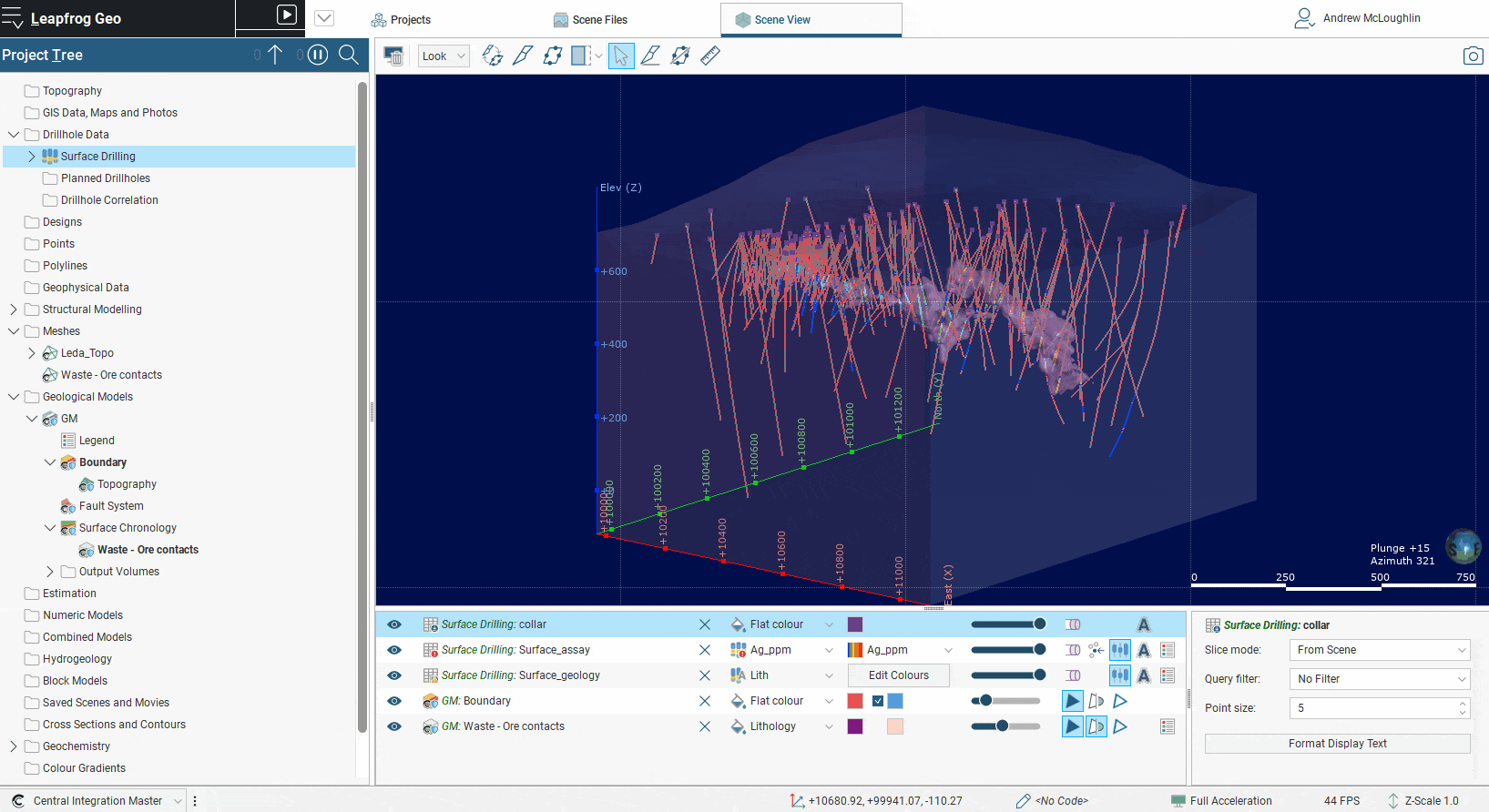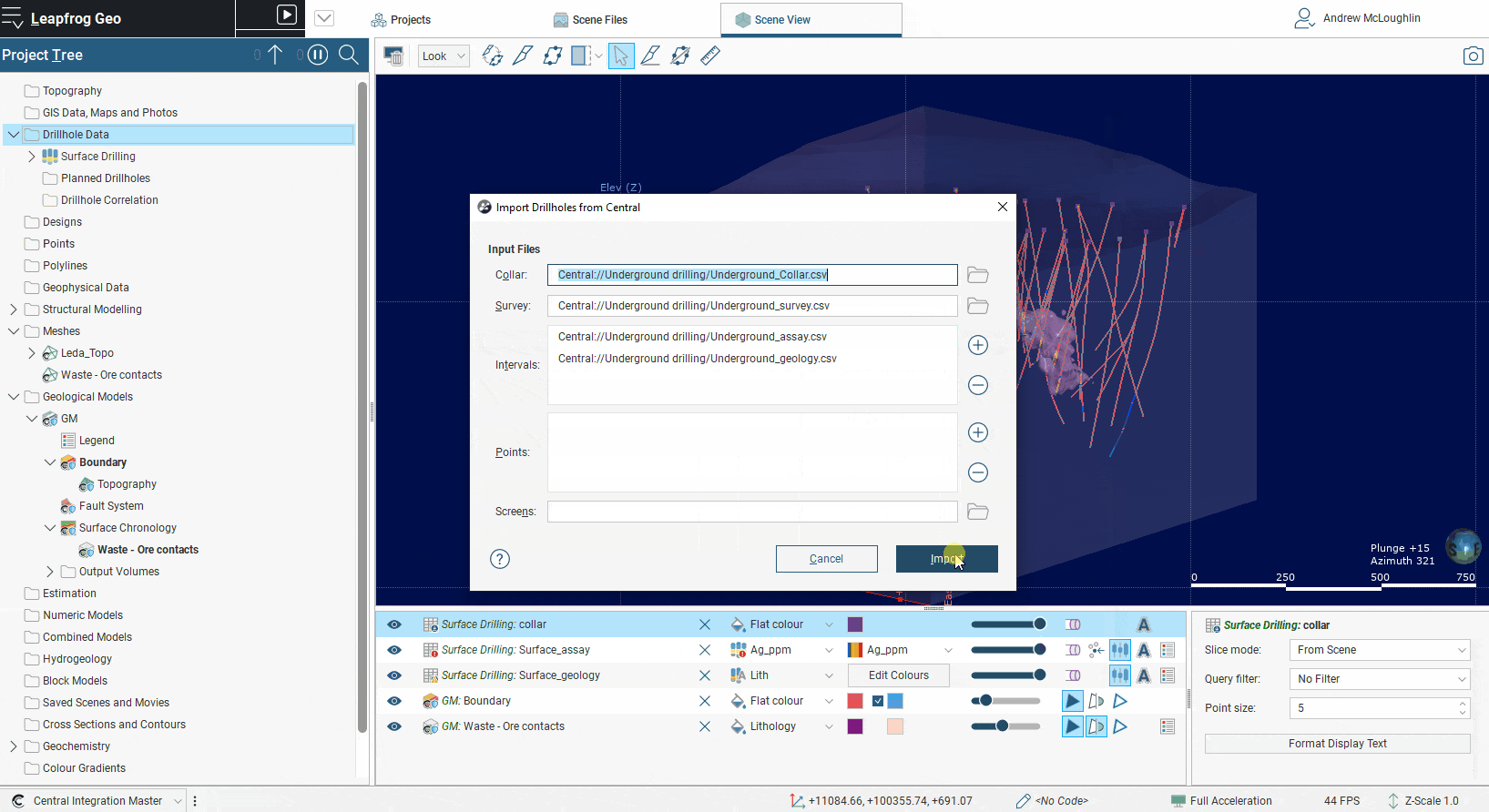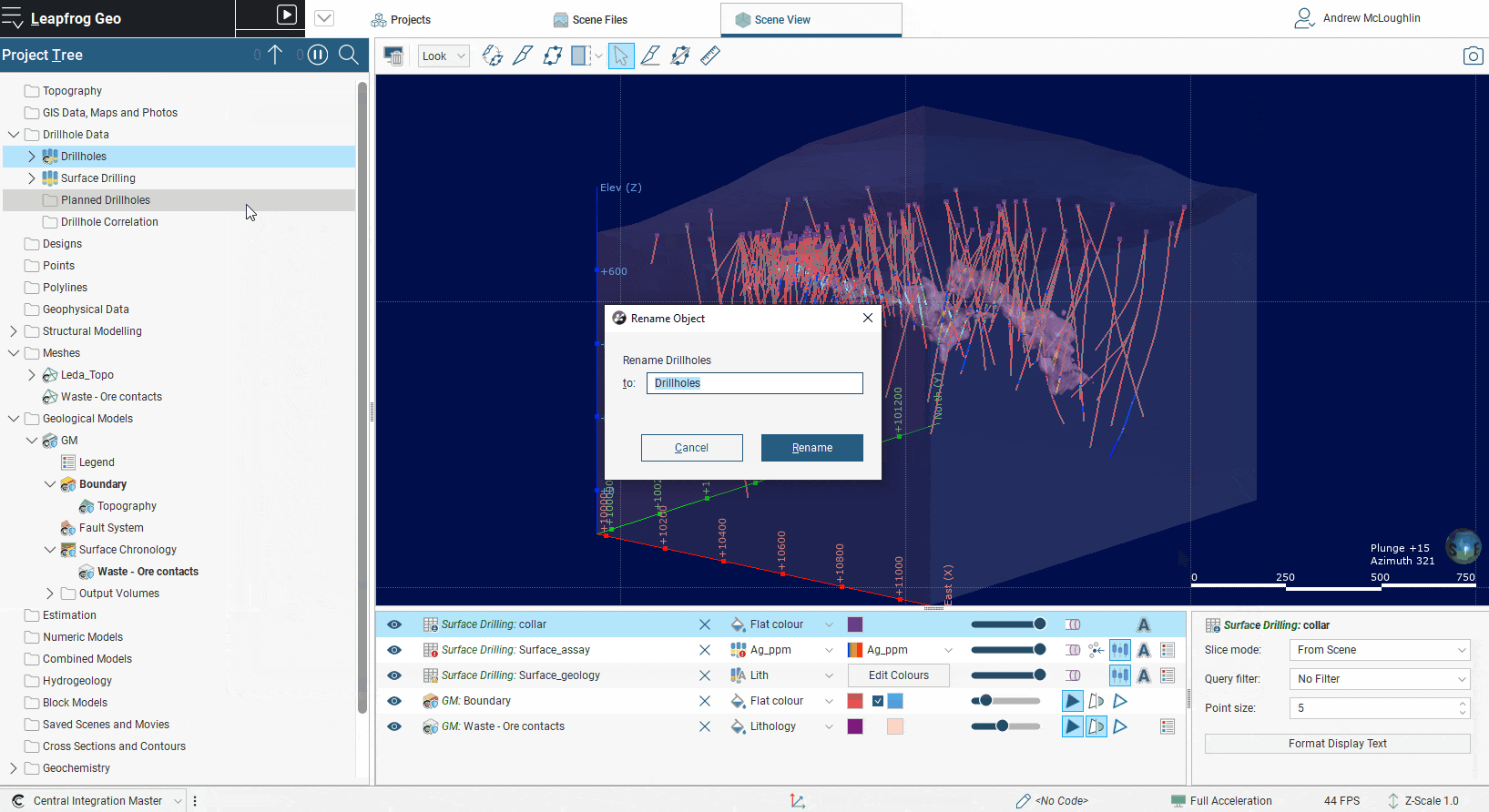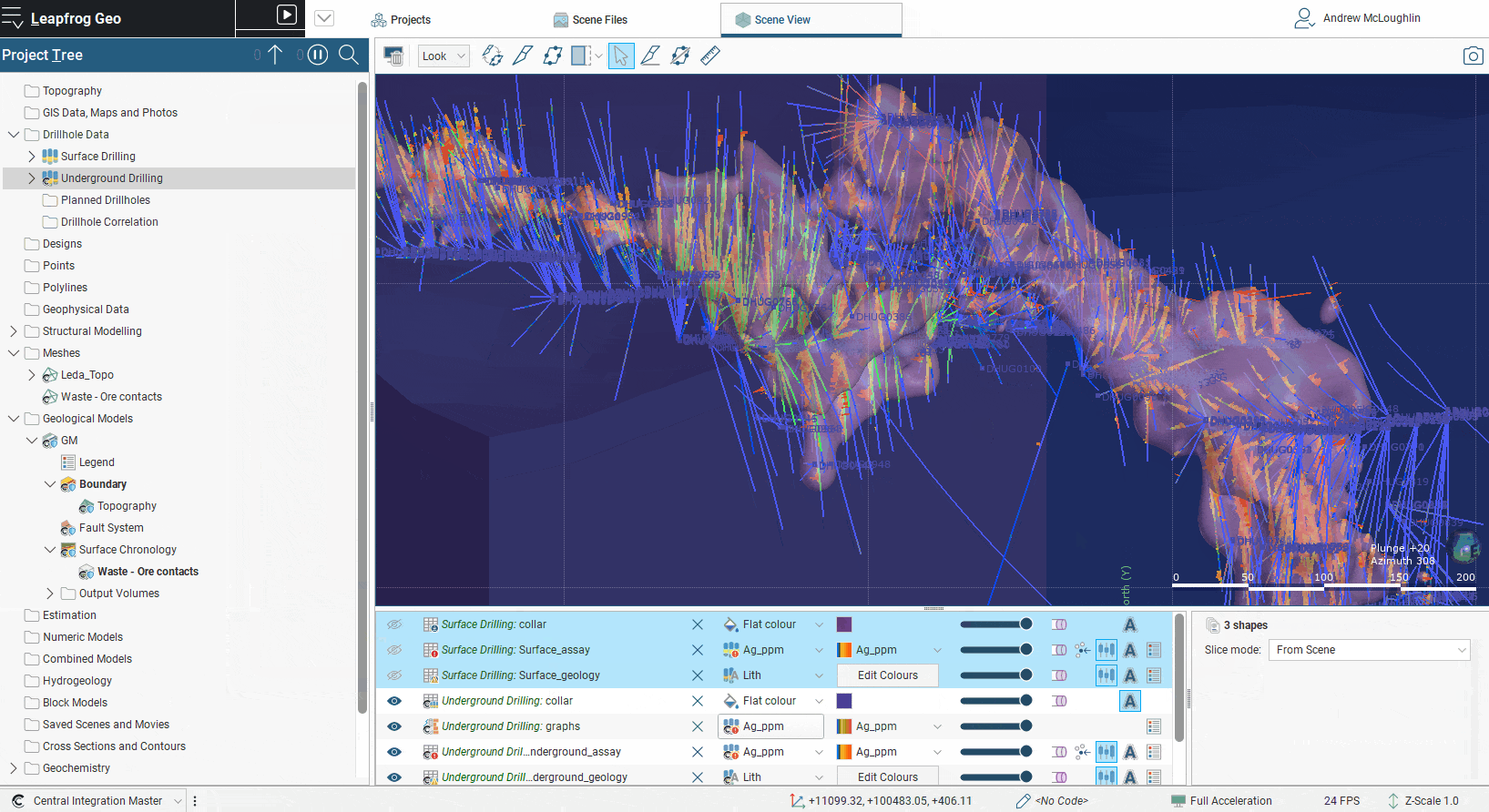
The current full functionality of the drillhole object is available within every drilling data set that is imported into the project. For each set you can perform validation, run compositing, create merged tables, import structural and point information and use all the other functions you currently enjoy. Drilling information cannot yet be combined across drilling sets, although the work is underway. However, data from multiple drill data sets can still be utilized in geological and numeric models within Leapfrog. Geological models only allow one base lithology column to be selected but surfaces within the model can be bolstered with data from multiple data sets using the “Add” data from “Other Contacts” options. This allows you to select contacts from any drill data set. Similarly, for numeric models additional numeric data from any drill data set can be added to the base values, opening the possibility of greatly improved workflows.
The drill hole correlation tool can now select collars from multiple data sets allowing for comparison of data between different sources. An interpretation table can be created, and this data will report to the drilling dataset that was assigned as the base interpretation column.
Keeping different data types separate
Consider the mining case where high-quality diamond drill data (DD) has been used to define a resource model prior to mining. This diamond drilling was logged in great detail and assayed for a large suite of elements. The pre-mining geological model was based on a refined grouping of the detailed data, but all information was imported to the base project.
After mining has commenced, cheaper reverse circulation (RC) drilling is to be used to progressively update and refine the model with closely spaced data ahead of excavation. Experience gained in building the preliminary resource, and now validated by mining has shown that only a reduced sub-set of the logging information is required, and only a few key elements. Previously, appending the RC data to the diamond drilling data in the preliminary resource required that the RC data tables be in exactly the same format as the tables in the original project, which often required considerable external file manipulation.
Now, the RC drilling information can be imported into the project as a separate drill data set, from a different data source if desired, leaving the original diamond drill data set untouched. And the contact information from the RC drilling can be used to update geological surfaces.
Similar workflows examples can be envisaged for the civil and environmental industries. For example, it is common for regulatory frameworks in these sectors to dictate the confidence levels that can be applied to different drilling types and to legacy or historic data. You can now import, and keep separate, data of different quality while still being able to use all data sets in model construction. Tools such as distance functions can then be used to classify the models based on proximity to different data sources.
Reduce the amount of reloading and downstream processing
Previously all new data had to be appended to a single drill data set, triggering processing of downstream objects unless specifically excluded from processing by a pre-build query filter. This was necessary, even to simply visualise and validate new data. Now, new information can be imported as a separate dataset and viewed/validated in comparison to existing information and to models already constructed, without triggering any reprocessing. You can then either append the verified data to an existing set, or add the data into models using contact points. The ability to visualise, validate and verify data prior to incorporating into models will streamline workflows for addition of new data making modelling and data analysis more efficient.
This fundamental change is the largest within Leapfrog since it was first released to market, the use cases for this feature are endless. Following directly on from this release, the next milestone on our roadmap – we are currently developing the interactions between the different drilling data sets, and how to merge them to create even more geological modelling value for you . The multiple drillhole, borehole and well data feature allows you to have greater control of your data and allows you to think of new and creative workflows within Leapfrog.