Lyceum 2021
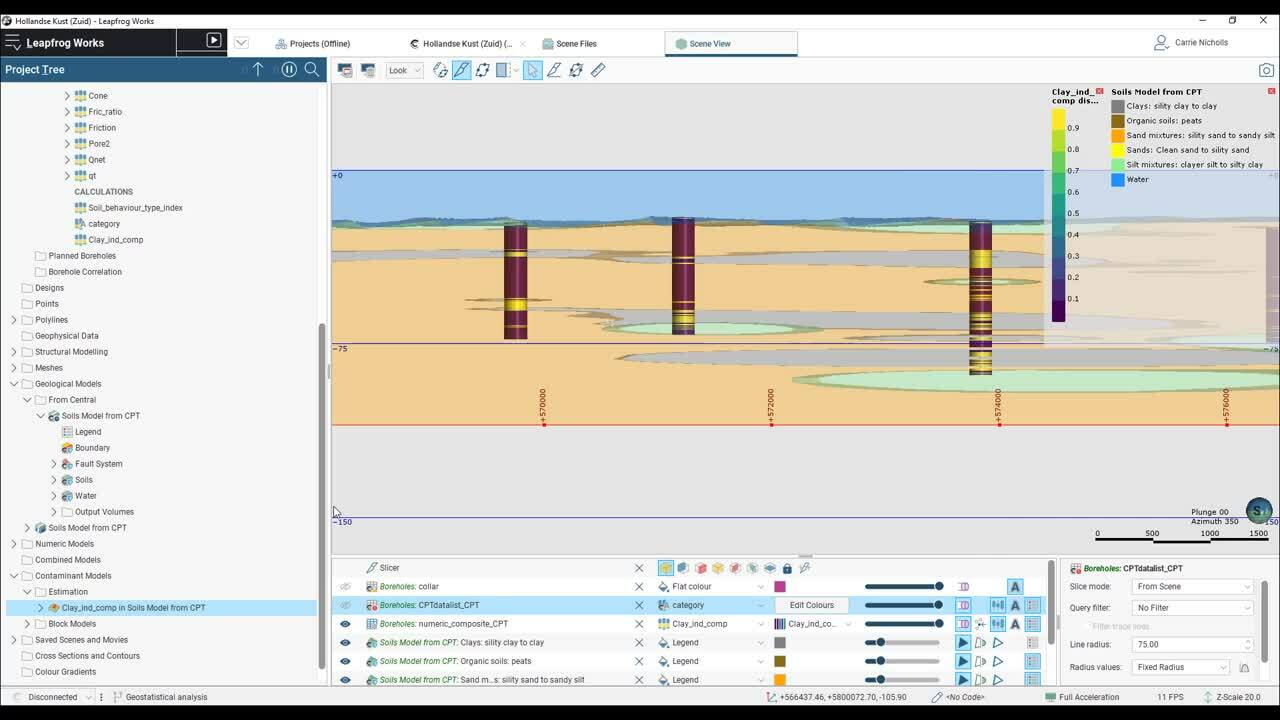
Discover how you can use Leapfrog to create a probabilistic model from CPT data.
This project uses borehole data from an offshore windfarm and during the session we will go through the steps to create an Indicator Kriged block model, in order to quantify the risk from clay in the soil profile.
Overview
Speakers
Carrie Nicholls
Customer Solutions Specialist, Seequent
Duration
20 min