Lyceum 2021 | Together Towards Tomorrow
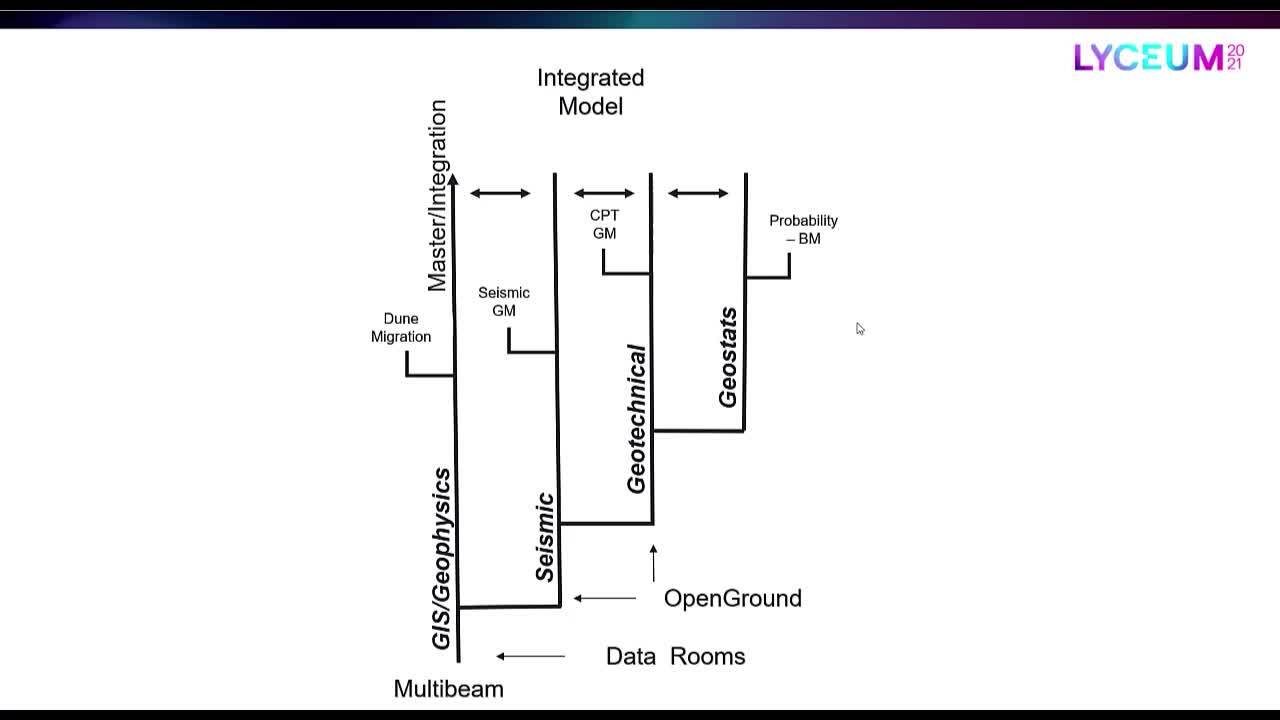
This presentation explores strategic approaches for overcoming common challenges associated with modelling large multi-disciplinary datasets for offshore windfarm development.
The challenges include managing and working with ‘big data’, collaborating across multiple disciplines, tracking updates and changes throughout the project cycle, and bringing it all together in a single integrated model.
Overview
Speakers
Nikhil Sen
Customer Solutions Specialist, Seequent
Becky Bodger
Customer Solution Specialist, Seequent
Duration
15 min